Methodology¶
The workflow management system used is snakemake, which orchestrates the execution following rules to concantenate the input/ouput files required by each step. The data cube in fits format is pre-processed using library spectral-cube based on dask and astropy. First, the cube is divided in smaller subcubes. An overlap in pixels is included to avoid splitting sources close to the edges of the subcubes. We apply a source-finding algorithm to each subcube individual.
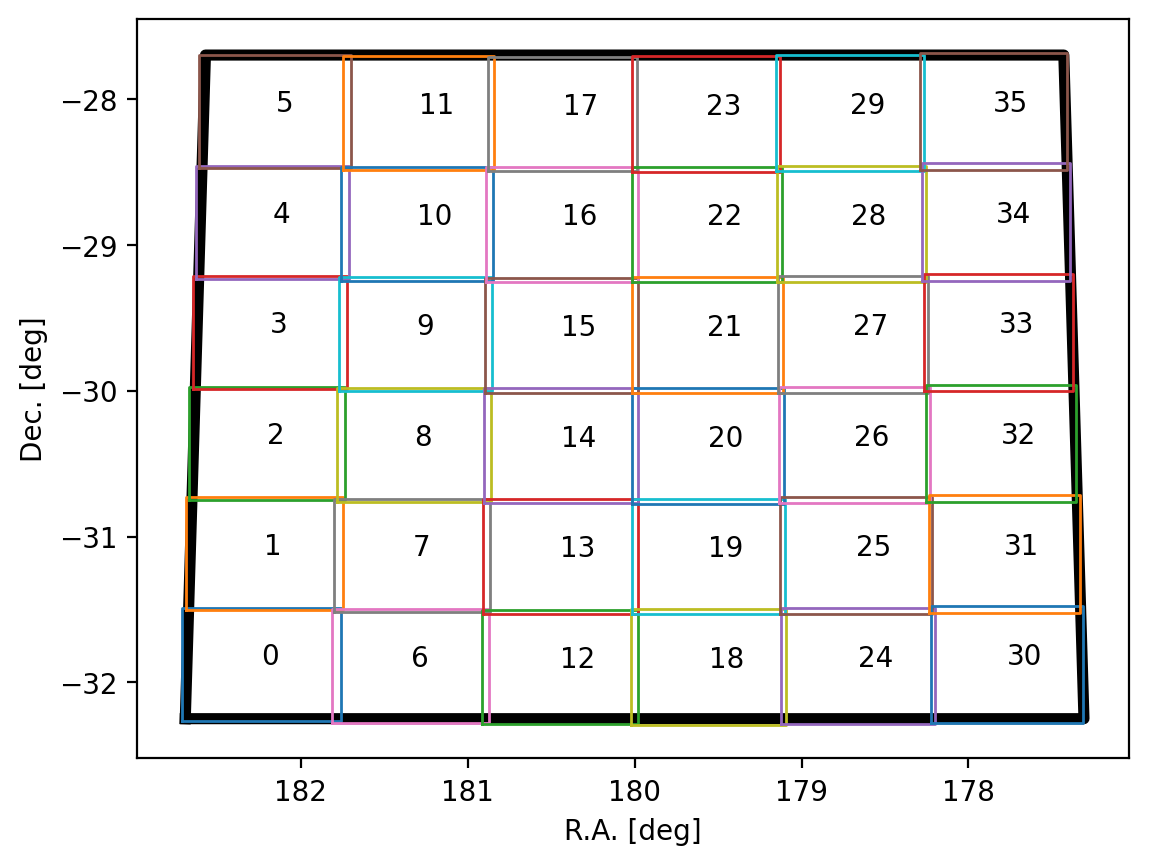
After exploring different options, we selected Sofia-2 to mask the cubes and characterize the identified sources. The main outputs of Sofia-2 used are the source catalog, and the cubelets that include small cubes, spectra and moment maps for each source are used for verification and inspection (this step is not included in the workflow and the exploration is performed manually). The Sofia-2 catalog is then converted to a new catalog containing the relevant source parameters requested by the SDC2, which are converted to the right physical units.
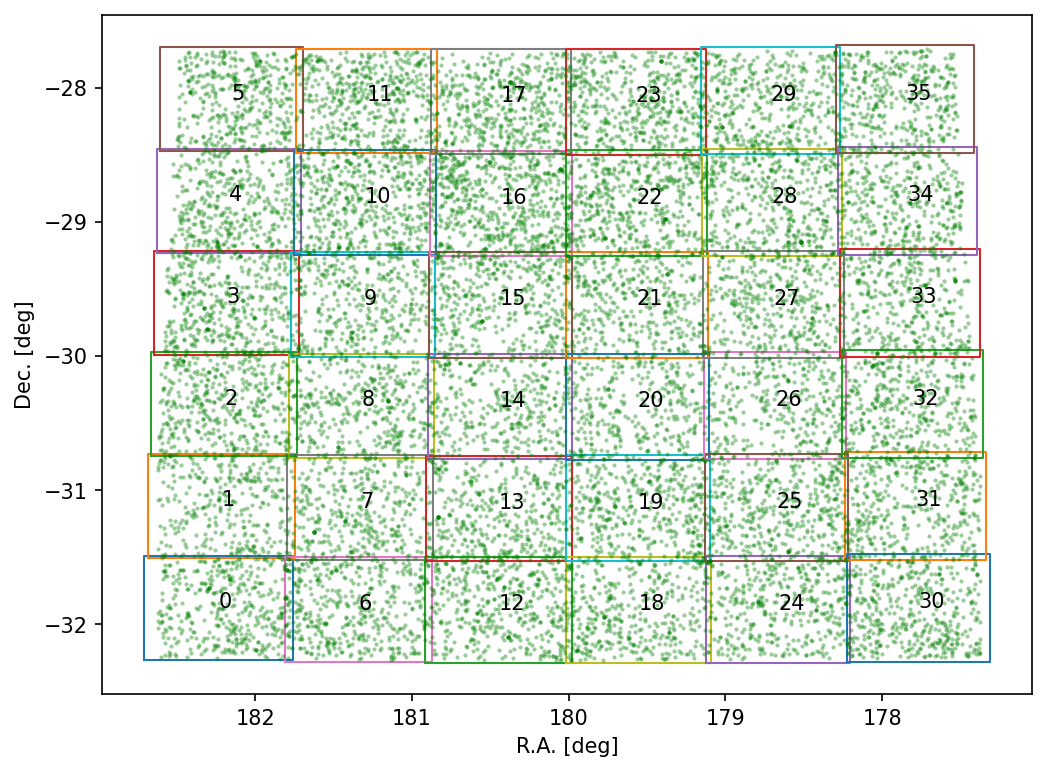
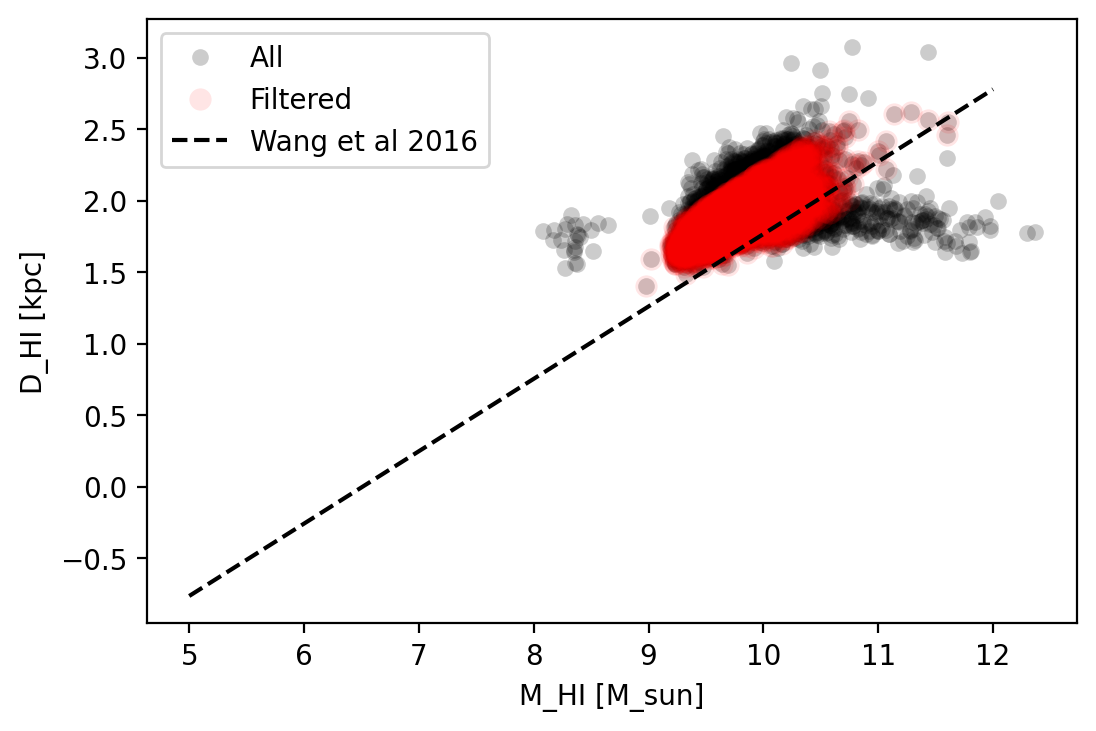
The next step is to concatenate the individual catalogs in a main, unfiltered catalog containing all the measured sources. Then, we remove the duplicates coming from the overlapping regions between subcubes using a quality parameter from the Sofia-2 execution. We then filter the detected sources based on physical correlation. We use the correlation showed in Fig. 1 in Wang et al. 2016 (2016MNRAS.460.2143W), which relates the HI size in kpc (\(D_HI\)) and HI mass in solar masses (\(M_HI\)).
Data exploration¶
We used different software to visualize the cube and related subproducts. In a general way, we used CARTA to display the cube, the subcubes or the cubelets, as well as they associated moment maps. This tool is not explicitly used by the pipeline, but it is good to have it available for data exploration. We also used python libraries for further exploration of data and catalogs. In particular, we used astropy to access and operate with the fits data, and pandas to open and manipulate the catalogs, matplotlib for visualization. Several plots are produced by the different python scripts during the execution, and a final visualization step generates a Jupyter notebook with a summary of the most releveant plots.
Feedback from the workflow and logs¶
snakemake prompts a lot of the information in the terminal informing the user of what step is being executed and the percentage of completeness of the job. snakemake keeps its own logs within the directory .snakemake/logs/. For example, this is how one of the executions starts:
Using shell: /bin/bash
Provided cores: 32
Rules claiming more threads will be scaled down.
Provided resources: bigfile=1
Job stats:
job count min threads max threads
-------------------- ------- ------------- -------------
all 1 1 1
concatenate_catalogs 1 1 1
final_catalog 1 1 1
run_sofia 20 31 31
sofia2cat 20 1 1
split_subcube 20 1 1
visualize 1 1 1
total 64 1 31
And then, each time a job is started, a summary of the job to be executed is shown. This gives you complete information of the state of the execution, and what and how is being executed at the moment. For example:
Finished job 107.
52 of 64 steps (81%) done
Select jobs to execute...
[Sat Jul 31 20:39:04 2021]
rule split_subcube:
input: /mnt/sdc2-datacube/sky_full_v2.fits, results/plots/coord_subcubes.csv, results/plots/subcube_grid.png
output: interim/subcubes/subcube_0.fits
log: results/logs/split_subcube/subcube_0.log
jobid: 4
wildcards: idx=0
resources: mem_mb=1741590, disk_mb=1741590, tmpdir=tmp, bigfile=1
Activating conda environment: /mnt/scratch/sdc2/jmoldon/hi-friends/.snakemake/conda/cf5c913dcb805c1721a2716441032e71
Apart from the snakemake logs, the terminal also displays information of the script being executed. By default, we save the outputs and messages of all steps in 6 subdirectories inside results/logs (see Output products for more details).
Configuration¶
The key parameters for the execution of the pipeline can be selected by editing the file config/config.yaml. This parameters file controls how the cube is gridded and how Sofia-2 is executed, among other options. The control parameters for Sofia-2 are directly controlled using the sofia par file. The template we use by default can be found in config/sofia_12.par. All the default configuration files can be found here: config.
Unit tests¶
To verify the outputs of the different steps of the workflow, we implemented a series of python unit tests based on the steps defined by the snakemake rules. The unit test contain simple examples of inputs and outputs of each rule, so when the particular rule in executed, their outputs are compared byte by byte to the expected output. The tests are passed only when all the output files match exactly the expected ones. These tests are useful to be confident that any changes introduced in the code during developement are producing the same results, preventing the developers to introduce bugs inadvertently.
As an example, we used myBinder to verify the scripts. The pipeline is installed automatically by myBinder. We executed the single command python -m pytest .tests/unit/ and obtained the following output:
jovyan@jupyter-hi-2dfriends-2dsdc2-2dhi-2dfriends-2dfsc1x4x2:~$ python -m pytest .tests/unit/
=================================================================== test session starts ===================================================================
platform linux -- Python 3.9.6, pytest-6.2.4, py-1.10.
rootdir: /home/jovyan
plugins: anyio-2.2.0
collected 6 items
.tests/unit/test_all.py . [ 16%]
.tests/unit/test_concatenate_catalogs.py . [ 33%]
.tests/unit/test_define_chunks.py . [ 50%]
.tests/unit/test_final_catalog.py . [ 66%]
.tests/unit/test_run_sofia.py . [ 83%]
.tests/unit/test_sofia2cat.py . [100%]
============================================================== 6 passed in 206.24s (0:03:26) ==============================================================
This demonstrates that the workflow can be executed flawlessly in any platform, even with an unattended deployment as offered by myBinder.
Software managed and containerization¶
As explained above, the workflow is managed using snakemake, which means that all the dependencies are automatically created and organized by snakemake using conda. Each rule has its own conda environment file, which is installed in a local conda environment when the workflow starts. The environments are activated as required by the rules. This allows us to use the exact software versions for each step, without any conflict. We recommend that each rule uses its own small and individual environment, which is very convenient when maintaining or upgrading parts of the workflow. All the software used is available for download from Anaconda.
At the time of this release, the only conflict with this approach is that Sofia-2 has not yet created a conda package for version 2.3.0 that is compatible with Mac, so this approach will not work in MacOS. To facilitate correct usage from any platform, we have also containerized the workflow. We have used different container formats to encapsulate the workflow. In particular, we have definition files for Docker, Singularity and podman container formats. The Github repository contains the required files, and instructions to build and use the containers can be found in the installation instructions.
Check conformance to coding standards¶
Pylint is a Python static code analysis tool which looks for programming errors, helps enforcing a coding standard and looks for code smells (see Pylint documentation. It can be installed by running
pip install pylint
If you are using Python 3.6+, upgrade to get full support for your version:
pip install pylint --upgrade
For more information on Pylint installation see Pylint installation
We runned Pylint in our source code. Most of the code extrictly complies with python coding standards. The final pylint score of the code is:





